I Have Built Realtime Conversation Assistant at a Hackathon

I thought the hardest part would be latency.
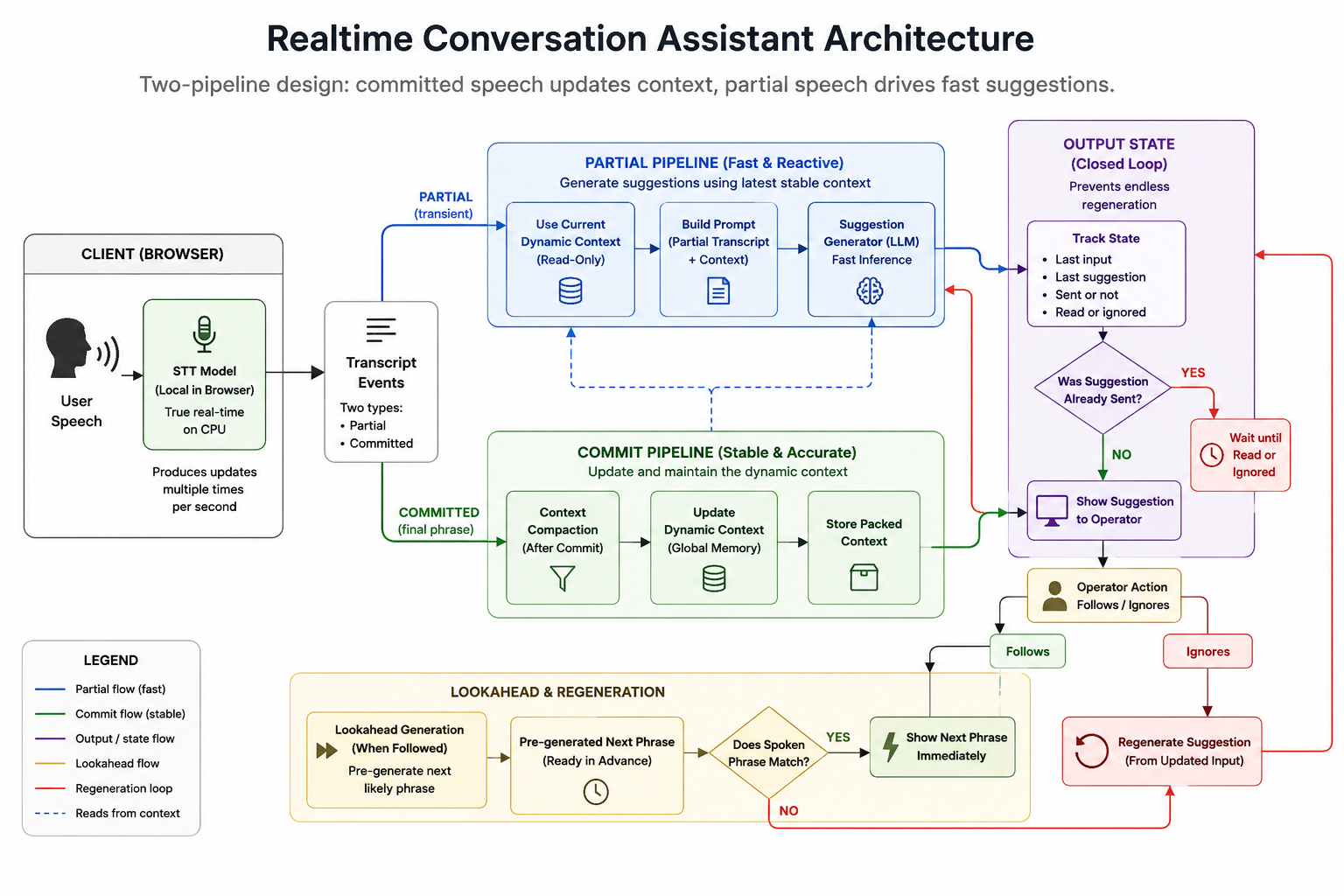
We were building a realtime conversation assistant: a system that listens to speech, understands conversational context, and generates suggestions fast enough for someone to actually use them during a live conversation.
On paper, the pipeline sounded straightforward:speech-to-text → context processing → LLM generation → suggestions.
In reality, everything broke once humans started talking. It went even worse when tested in the middle of crowded open space during the hackathon.
Speech recognition rewrote words retroactively. Partial transcripts arrived multiple times per second. Suggestions regenerated so often they became unreadable. Faster reactions made the system worse, not better.
The biggest realization came surprisingly early:realtime systems are not about maximum responsiveness. They are about rhythm.
This article is a technical breakdown of what we built during a 24-hour hackathon, what completely failed, and what unexpectedly started working once we stopped treating the system like a chatbot and started treating it like a live conversation participant.
The assumptions
First assumption was: real-time is hard. It requires careful timings, ensuring everything happens as a flow. While it’s trivial to stream responses from LLM models - it is not possible to stream TO the LLM, adjusting context and input on the go.
Real-time text-to-speech matched with on-the-go text generation seemed almost impossible. Latency for converting TTS (text to speech) and time necessary for generating the suggestions seemed to be the very tricky. We thought in the worts case scenario existing APIs will help us to deal with it.
Apart of system feeling delaying crucial responses (suggestions) - suggestions being derailed from the topic seemed to be another challenge. Multiple pre-processing jobs running in parallel before generation was supposed to help with it.
When the pipeline finally worked
First great finding was a model being able doing STT (speech to text) directly in the browser. Any browser. Virtually any machine. Using pure CPU and being a true real-time model. Performing conversion on the go and once phrase is over - revalidating and adjusting. Doing surprisingly well for the local model running directly in the browser.
Once we have text - the decision was straightforward. Using WebSockets for low-latency exchange between client and the server. This also perfectly matched my expectations of using my favorite event-driven approach.
Once we deliver text to the server - we start processing it immediately. Remember those multiple parts processing in parallel? The concept was almost right:
- one worker was categorizing input for additional context to be past to the generator
- second worker was processing the same input and adjusting the global context. We called it “dynamic context”. I’ll describe details a bit later.
Finally, once input is categorized and context is updated - it all gets delivered to the generator - LLM that generates the suggestions.
Once it all worked and we saw reactions to our speech - it felt like a first success. I thought we are at 40% of success of the project, but I felt like we have barely passed the 10%. And my gut feelings were right.
The Opposite Problem: Too Reactive
Visual logs was one of the first parts that was implemented directly in the browser. This gave overall understanding of the system lifecycle. It helped to follow the problems, but was not making us closer to the solutions.
First of all: transcriptions from STT were coming multiple times per second. These were incomplete and often had too big diff between the versions. Because partial transcriptions from incomplete words were rewritten, sometimes affecting previous words regressively. Once pause was registered - model’s been recalculating entire phrase and sending final version. I knew it is too late to start the generation.
On the other side - triggering 3-5 generations per second was causing the worst effect - generated suggestions were replaced 3-5 times per second. LLM, being non-deterministic were doing it’s best generating different results each time.
First solution? Delay based debounce and cancelations. Solved the “suggestion replaced too fast” problem and got us back to not enough responsible problem. And sometimes - too responsible again, when speech tempo was overall lower. These were first realizations what are the real problems.
Real-time processing requires rhythm, tempo. Not maximum reactivity to external events. This started to move us towards the states.
State Became more important than Intelligence
We had 2 type of events coming from STT model: partial and committed. Both processed equally. Both triggering the same flow. Cancelling and overlapping with each other. The gut feeling was saying processing committed for generation is too late. That’s how pipeline got split into 2 parts. And the state was introduced.
The state was storing all the existing information and was passed to generator. But the way state was updated changed a lot. Committed aka fully transcribed phrases were triggering context compaction. At this point we were absolutely sure what was said. Said and finished. No way to get back. So that became a perfect moment for updating the context.
The second pipeline kept going on partial transcriptions. It was using already existing and packed context and triggering generator with one task: generate a completion for the phrase.
A minimalistic output state was introduced to connect output to the input and finally preventing partials endlessly prevent generation or endless regeneration. System knew exactly what was passed as input, what was generated and whether it was sent. Once it was sent - generation was stopped until it was read. The other case when regeneration must happen - when operator ignored the suggestion and was not following the generation. Finally it became a closed-cycle system.
The Surprising Failure of “Smarter” Models
The biggest problem? “How are you?” was getting “I’m good, what about you?” responses. Constantly. Endlessly. Instead of suggesting continuation for the question or next phrase - it was answering it. Tons of prompts and evaluation were barely helping. Until I started challenging my decisions regarding the models.
Newer & better - turned out to be reasoning models. Our goal was to get stable <500ms responses. We ended up having 150-300ms. But reasoning models had no chance to fit.
Larger models like 7b, 8b - were not fast enough. After all - the tiny 1.5b and 2b models that were supposed to be “helper” models for context and categorization - became a generation model. Tweaking prompt and providing more and more example finally did the trick. We were getting acceptable suggestions that were continuation of the phrase.
Realtime UX is Psychological
I knew there was one very important goal: reliability. It was obvious some experience was necessary for using the system, but it was clear operator must be able to rely on the system. Once operator goes to “reading” mode and following suggestions - we must not overreact and change our suggestions. On the other side - we must deliver new portions in time. All these are necessary to create one feeling: system is working, it’s responsive enough and I don’t sound weird. Except it was failing it.
Remember those debounce mechanisms? Once states were introduce these became obsolete and messed the responsiveness completely. It was working wrong. It was getting late. And human brain being fatigued was giving up. Luckily - hackathon was very well organized in terms of snacks, beverages and freedom. Walk combined with beverages allowed to squeeze some more power to drop parts that were obsolete. This was the moment I realized again: time-based decisions/delays are often wrong. But let’s get back to the pipeline.
Finally we were able to start conversation and continue it by simply reading suggestions from the screen. This was the point where we were approaching 40% for real.
What actually started working
State were ensuring pipelines were triggered at the right point. However, still being afraid responsiveness might be not enough and remember confidence is one of the core attributes for this system - optimization started.
First of all - lookahead generation. Once we generated the end of the current phrase - we were able to generate the very next phrase. Sounds simple. And luckily my mental model was already up to date to understand - it requires reconciliation. If phrase that was said completely matches suggestion - we can show pre-generated phrase immediately. It was it!
And now it was the time to pay attention what exactly was generated. Playing with STT in a crowded and loud open space during the 24h hackathon is not trivial. So small tricks were implemented, like Push To Talk for explicit commits and the global context field. This was meant to help generator to follow the general direction of the conversation, preventing switching to the random topics and suggesting... well, completely unrelated stuff. We were frustrated and called it... bad suggestions :D
We had an idea of tool being able to navigate us through the upcoming pitch. The tool that sells itself. The way we’ve been testing it’s ability to follow the general context - we were introducing side story during the conversation. And during one of the runs I wasn’t following the screen. But when I heard what was said - I was amazed! It was able to complete phrase about falling down while skating and politely navigated conversation back to the pitch we’ve been testing.
This was the point I knew we’re approaching 50% success.
The dynamic context was working well and despite repacking latest portions on top of existing context - it was able to follow the initial topic and direction. I personally love this part most of all. It shows the real power of tiny models being able to determine what matters and what can be dropped. Not always successfully, though.
What the Hackathon Changed for Me
First of all - small models are much more useful that I thought. After all entire setup was running on Macbook Air with 16GB of RAM - pretty popular machine these days. Fully locally and autonomously.
Second lesson: assistance is different from answering. There is no comfort of knowing exactly what we are reacting to. We’re not reacting - we must follow along. And it changes everything.
Third outcome: I’m not afraid of complexity of real-time systems and generation latency. Machines aren’t smarter, has no intuition and feelings. But it can do operations in parallel, at the same time. And this is what makes it hard for us to understand and follow the parallel processing. But the realtime requires a bit more than that - catching those tiny, small moments that are exactly the right moments.
Finally: at that moment there was no API available from big-tech companies that would be helpful for us to replace the entire pipeline we have built. Most of the real-time conversation AI are turn based. LLMs are not meant for partial context commits.
Open questions
Luckily hackathons are limited in time. Those limits are blessing and a curse. Blessing, because it doesn’t allow engineers to dig endlessly. Therefore we ended up with many ideas and questions we had a chance to discuss after the finale.
How to better handle conversational turns? Which sub-processors should be added to navigate generation even better?
And some question that were left undiscussed: how to adjust pipeline to the tempo? In a very short timeframe how to ensure suggestions are at least acceptable?
At what point LLM takes over the conversation and it becomes performance and manipulation, bringing it to the best tech competition?
Closing reflections
I like building. I like working in project mode. I like challenges. Hackathon gives all I need. But it also demands a lot. It is not enough to bring the knowledge and competences. Experience is not reliable when approaching new areas. It requires open-minded approach. Being honest with yourself and teammates about now knowing. Owning failures. And still be happy about those. Because each failure moves us towards the big goal.
We haven’t won the hackathon. But that was not something even close to the failure. It’s been a great lesson and a challenge. And that’s exactly what I wanted it to be.
There are many ways such assistant could be used, and we have generated half a dozen scenarios and angles to pitch it. In reality I believe such systems shall not be used by humans in long term. It might become a great workout, education and practice mechanism. And I believe humans must stay humans, relying on their own skills and sharp minds.


